Cela faisait bien longtemps que je n’avais plus rien posté ici, mais me revoilà.

Intro : l’infrastructure technique de l’association
meteo06.fr est le site Internet de l’association du même nom (enfin presque). C’est un WordPress, permettant aux différents membres de l’équipe de rédiger des prévisions, des articles de « vigilance« , des récapitulatifs climatiques, etc., de manière simple et ludique.
Ce site héberge aussi les données des stations météorologiques déployées/maintenues par l’association, via autant de sous-domaines qu’il n’y a de stations. Par exemple, ma station personnelle située sur les collines de Nice Pessicart est hébergée sur un mini-site (développé par nos soins) sur nice-pessicart.meteo06.fr. Et ses données brutes dans une base de données MariaDB.
Jusque là rien de bien compliqué. Vient s’ajouter une multitude de scripts pour générer de la climatologie aux normes OMM, envoyer les données de nos stations éligibles à des partenaires comme l’association Infoclimat avec son réseau StatIC, ou encore l’association ROMMA. On héberge également une instance de MyBlitzortung, avec une base de données référençant tous les impacts de foudre détectés par le réseau sur le domaine de l’Europe.
On a également mis en place un VPN pour connecter les Raspberry Pi qui se situent sur les stations météo…
D’un point de vue de l’hébergement, tout ce petit monde est hébergé sur un serveur dédié, payé par l’asso. En réalité, il s’agit d’une VM, hébergée sur un serveur physique Start-2-M-SSD de chez Online.net Scaleway. Cette VM est poussée par VMware ESXi, et jusqu’ici tout allait bien. Nous ne sommes pas très gourmands en stockage et donc ce serveur et ses 250 Go de SSD nous suffisent.
Et en fait l’infrastructure technique se résume quasiment à cela (on ajoutera juste un autre serveur pour du backup chez Kimsufi, et un NAS… pour du backup aussi). Vous comprendrez donc pourquoi j’ai mis le mot infrastructure en italique ;-).
J’avais dans un premier temps alloué 100 Go à la VM, puis 150, et très récemment j’avais poussé l’allocation à 200 Go pour un peu plus de confort voyant le disque se remplir petit à petit. En allocation dynamique. Et c’est là que tout bascule.
ESXi et l’allocation dynamique
L’allocation dynamique est très pratique sur le papier, surtout si on a de la place et de l’argent. Le concept est simple, on alloue une quantité de stockage à une VM (et donc on lui fait croire qu’elle en dispose), mais en arrière-plan, VMware ne lui donne que ce dont elle se sert réellement. On peut donc allouer de l’espace de stockage « partagé » à une autre VM sans forcément tout péter tant qu’on surveille.
Jusqu’ici tout va bien.
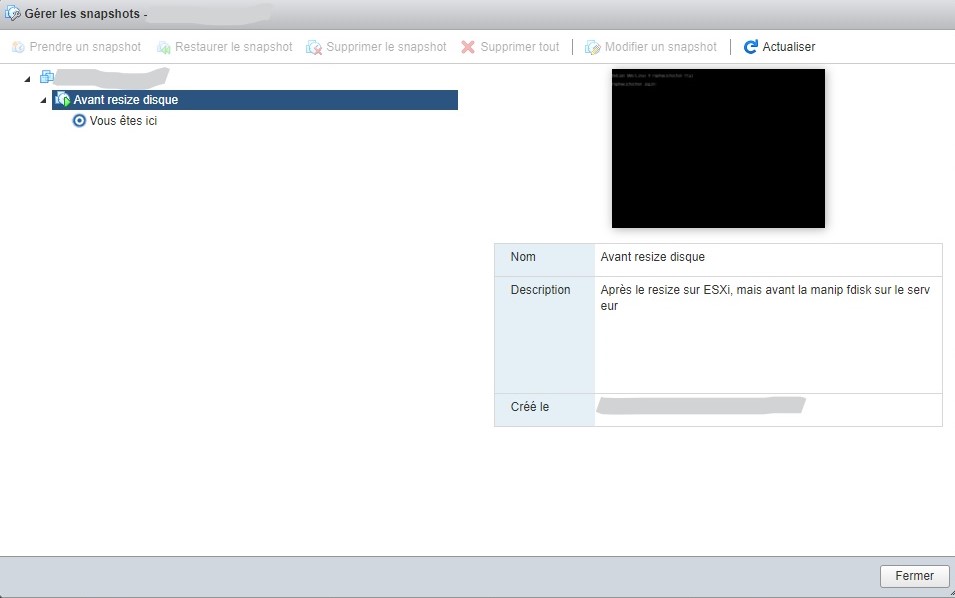
Agrandir l’allocation disque d’une VM sous Linux
Comme indiqué, j’ai récemment augmenté la taille du disque de la VM, pour lui ajouter 50 Go. Et c’est assez simple à faire ! Taille du disque avant modification :
Dans un premier temps on augmente dans l’interface ESXi la taille du disque de la VM en question, après avoir fait un snapshot (au cas où ça foire et que l’on veuille retourner en arrière)
Il faut ensuite augmenter la partition du système invité, ici un Debian 9 (la fameuse VM de l’association Météo06).
Pour cela, j’ai fait très simple et j’ai redémarré la VM sur un live CD de Gparted : redimensionnement de la partition via une GUI.




Tadaam : en redémarrant notre VM, on se retrouve avec un disque plus gros :
Jusqu’ici tout va bien.
Freeze de la machine en pleine nuit
La nuit, c’est l’heure des backups (entre autres).
Lundi matin, nouvelle semaine, et… mauvaise nouvelle, la VM semble hors ligne depuis 2h du matin…
Rien ne va plus.
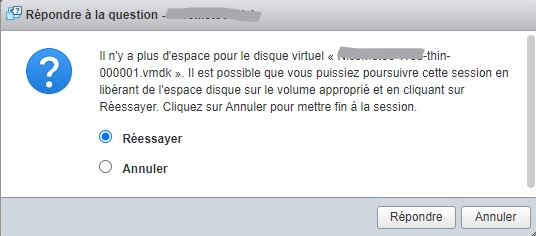
Et catastrophe, elle ne veut pas se relancer !
J’ai beau tenter de faire de la place sur le datastore depuis l’interface d’ESXi (suppression de vieux ISO, logs…), rien à faire !
En fait, je me suis fait avoir par le combo allocation dynamique + snapshot, qui finit par prendre plus de place que l’espace disponible sur la machine (environ 230 Go disponibles pour les VM).

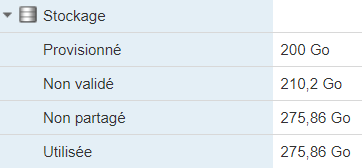
Et évidemment il est impossible de lancer une consolidation des disques puisque c’est une opération qui a également besoin d’espace temporairement.
Le point de non-retour est atteint, sans même s’en être rendu compte, sans un avertissement… C’est ma faute, et il faut trouver une solution !
Besoin d’espace disque
Peu importe la stratégie, il va me falloir de l’espace disque à disposition. Heureusement je dispose d’un autre serveur Kimsufi (pour les backups, souvenez-vous), avec un disque (HDD) de 2 To.
ESXi nous permet de monter un partage NFS, ce que je fais, et nous voilà partis pour 12 longues heures de copies, du datastore1 vers le partage NFS. Le réseau vers un Kimsufi n’est vraiment pas terrible, et en même temps c’est normal vu le prix !
Cela me laisse 12h pour réfléchir à une stratégie :
- Une fois copié sur le partage NFS, je tente de recréer la VM depuis ce dernier (plutôt que depuis le datastore), me permettant peut-être d’effectuer une consolidation des disques. Démarrer la VM depuis le partage NFS ? Je n’ose pas, la latence est tellement énorme que j’ai peur de faire pire.
- Je prends temporairement une machine plus grosse (500 Go de disque) chez Scaleway, une fois la copie terminée sur le partage NFS, je monte ce dernier sur la nouvelle machine Scaleway (avec ESXi d’installé) et je recopie de nouveau dans l’autre sens les fichiers de la VM. Là j’effectue une consolidation des disques, je démarre la VM, et j’avise.
Je finis par choisir la deuxième option, qui me forcera à attendre de nouveau une dizaine d’heures pour effectuer la copie entre le partage NFS Kimsufi et ce nouveau serveur Pro-6-XS de Scaleway. Cela me permettra peut-être temporairement de relancer la VM et donc tous les sites Internet (et la récupération des données des stations). Pour ensuite pouvoir l’éteindre proprement.
PS : Petit détail, ne laissez pas le SSH de l’hôte ESXi démarré toute une nuit sans être connecté sur une console.

Il en résulte d’autres problèmes au petit matin, fort désagréable, et obligeant à un reboot électrique du serveur : une impossibilité de se connecter (compte root bloqué) après qu’un certain nombre de tentatives de connexion sur le compte ait échoué.
Consolidation, démarrage de la VM
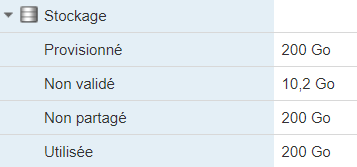
Une fois la copie terminée, et la VM ajoutée sur ce nouveau serveur/hôte ESXi, on lance la consolidation des disques. D’ailleurs l’interface me le propose immédiatement après l’ajout de la VM. Cela prendra environ 13 minutes, et nous permettra de réduire l’utilisation disque de la VM de 275 à 200 Go.

Réplication MySQL corrompue
Je le disais plus haut, les données des stations météo sont récupérées via un Raspberry Pi sur place, qui fait tourner le superbe logiciel WeeWX et qui enregistre dans une BDD locale MySQL chaque enregistrement. Pour récupérer les données sur le serveur de Météo06, j’ai mis en place une réplication Maitre->Esclave Primaire->Réplique entre le RPI et le serveur. La BDD primaire est donc le RPI, et la Réplique est le serveur Météo06.
Sauf qu’évidemment, le serveur s’étant arrêté brutalement…
Finalement ça se résout assez simplement :
Et maintenant ?
On passe d’un serveur qui nous coûte 30€ HT, à un serveur à plus de 70€ HT !
C’est cool, il tourne mieux, c’est plus rapide, plus confort (on a doublé la taille du disque SSD), et en plus il est sur DC5, mais… il est cher !
Il faut donc réussir à revenir sur notre serveur Start-2-M-SSD à 30€ HT. Deux solutions viennent à moi :
- J’en profite pour repartir de zéro : installation fraîche d’un Debian et reconstruction petit à petit de toutes les briques nécessaires sur notre serveur historique. Avec ou sans VMware ESXi ? Bonne question… Dans un cas comme dans l’autre, c’est beaucoup de travail et surtout beaucoup de temps (que je n’ai pas forcément en ce moment). Avec le point positif de repartir de zéro et donc de pouvoir appliquer de nombreuses best-practice que j’ai appris (souvent à mes dépens) ces dernières années.
- Un peu plus délicat, qui va demander encore quelques heures de downtime, mais moins chronophage pour moi : shrinker (réduire) la partition root de ma VM (avec GParted et les risques que cela implique). Puis transférer de nouveau la VM sur notre serveur historique.
On a un mois pour faire ça et résilier la machine à 70€ HT !
Si je ne l’ai pas déjà précisé, nous sommes une association avec des moyens limités (tant en coût qu’en humain).
Et en effet on est obligé de faire des concessions par endroit (sauf les backups !).